Over the last few months I have been compiling information that I have used to help customers when it comes to PSO. Using Helm and PSO is very simple, but with so many different ways to setup K8s right now it can require a broad knowledge of how plugins work. I will add new samples and work arounds to this Github repo as I come across them. For now enjoy. I have the paths for volume plugins for Kubespray, Kubeadm, Openshift and Rancher version of Kubernetes. Plus some quota samples and even some PSO FlashArray Snapshot and clone examples.
This post is a recap of my session at VMworld last week in Las Vegas. First, due to lighting, the demo was no very easily viewable. I am really disappointed this happened. I posted the full demo here on youtube:
All of the scripts and instructions are available here on my github repo.
One thing since we released Pure Service Orchestrator I get asked is, “How do we control how much developer/user can deploy?”
I played around with some of the settings from the K8s documentation for quotas and limits. I uploaded these into my gists on GitHub.
git clone git@gist.github.com:d0fba9495975c29896b98531b04badfd.git
#create the namespace as a cluster-admin
kubectl create -f dev-ns.yaml
#create the quota in that namespace
kubectl -n development create -f storage-quota.yaml
#or if you want to create CPU and Memory and other quotas too
kubectl -n development create -f quota.yaml
This allows users in that namespace to be limitted to a certain number of Persistent Volume Claims (PVC) and/or total requested storage. Both can be useful in scenarios where you don’t want someone to create 10,000 1Gi volumes on an array or create one giant 100Ti volume.
Credit to dilbert.com When I searched for quotas on the internet this made me laugh. I work with salespeople a lot.
The sessions are filling up so it will be a good idea to register and get there early. I am very excited about talking about Kubernetes on vSphere. It will follow my journey of learning containers and Kubernetes over the last 2 years or so. Hope everyone learns something.
Last year, here I am talking about containers in front of a container. Boom!
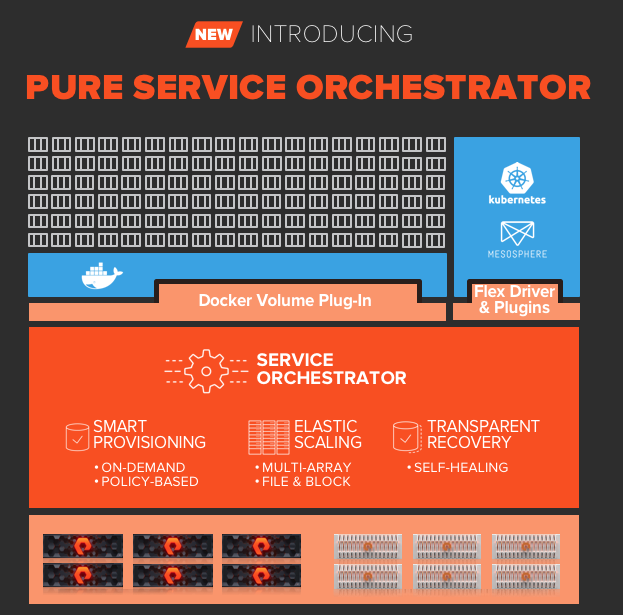
At Pure we have been working hard to develop a way to provide a persistent data layer that is able to meet the expectations of our customers for ease of use and simplicity. The first iteration of this was the release as the Docker and Kubernetes Plugins.
The plugins provided automated storage provisioning. Which solved a portion of the problem. All the while, we were working on the service that resided within those plugins. A service that would allow us to bring together managing many arrays. Both block and file.
The new Pure Service Orchestrator will allow smart provisioning over many arrays. On-demand persistent storage for developers placed on the best array or adhering to your policies based on labels.
The second way that may fit into your own software deployment strategy is using Helm. Since using Helm provides a very quick and simple way to install and it may be new to you the rest of this post will be how to get started with PSO using Helm.
Installing Helm
Please be sure to install Helm using the correct RBAC intructions.
You can run a dry run of the installation if you want to see the output but not change anything on your cluster. It is important to remember the path to the yaml file you created above.
Since we do not want to assume you only have Pure Storage in you environment we do not force ‘pure’ as the default StorageClass in Kubernetes.
If you already installed the plugin via helm and need to set the default class to pure run this command.
kubectl patch storageclass pure -p '{"metadata": {"annotations":{"storageclass.kubernetes.io/is-default-class":"true"}}}'
If you have another storage class set to default and you wish to change it to Pure you must first remove the default tag from the other StorageClass and then run the command above. Having two defaults will produce undesired results. To remove the default tag run this command.
Maybe you are a visual learner check out these two demos showing the Helm installation in action.
Updating your Array information
If you need to add a new FlashArray or FlashBlade simply add the information to your YAML file and update via Helm. You may edit the config map within Kubernetes and there are good reasons to do it that way, but for simplicity we will stick to using helm for changes to the array info YAML file. Once your file contains the new array or label run the following command.
Next step in learning helm is being able to take an existing helm package and put it in your own repo.
There are ways to do this with github pages. I don’t really want mess withthat right now, how can I use a Github repo to host my changes to the deployment?
For installing helm and an additional demo please see part 1 of this series.
Over the last few weeks I was setting up Kubernetes in the lab. One thing I quickly learned was managing and editing yaml files for deployments, services and persistent volume claims became confusing and hard. Even when I had things commited in github sometimes I would make edits then not push them then rebuild my K8s cluster.
The last straw was when 2 of our Pure developers said that editing yaml in vi wasn’t very cool and to start using helm.
Needless to say that was good advice. I still have to remember to push my repos to github. Now my demostration applications are more “cloud native”. I can create and edit them in one environment and use helm install in another and have it just work.
One request from customers is not only provision persistent storage for Kubernetes but also integrate into workflows that may need to snap and copy the data for different environments. Much like we do this with powershell or python for SQL and Oracle environments to accelerate development or QA. Pure has enabled snapshots using the Pure Provisioner as part of our Kubernetes Plugin.
In this demo I am showing how I can take a users data directory for JupyterHub and clone it for another user to take advantage of all the benefits of Pure’s snapshots and clones. You instantly get access to a copy of the dataset. The dataset doesn’t take up room on the backend storage. Only globally unique changes will grow the volume. In this use case the Data Science team will see increases in productivity as they are not waiting for data to download from the cloud or copy from another place on the array.
The command to run the snap using kubectl is below:
Make sure the follow the directions on the page to pull and install the plugin. If you are using Openshift pay special attention to the Readme. I will post more on this in the near future.
Cockroach DB as our Persistent Database
I want to simulate a very easy database that I can easily use in a container. That is also not the same old. I built a Go app that will write to a database over and over to kind of demonstrate the inner workings of the plugin but not necessarily supply a performance test.
With that said, please check out how to deploy and scale a database with a persistent data platform from a Pure FlashArray. Watch this in Full screen to make the CLI commands easier to see.
What you are seeing in the video:
Deploy the initial 3 pods with volumes automatically created and connected on the Pure FA.
Initialize the cluster.
Fail a node and watch K8s redeploy a new container and re-attach the data volume.
Run a load generation application as a K8s Job.
Scale the DB cluster out to 8 nodes.
What is next?
This is a really easy and quick demo but it show the ease of using the Pure Plugin to manage the persistent data, making sure you do not lose data in the event of app crashes. Also easily scaling. This can all be done via policy and the deployment can be made even easier using Helm. In a future post we will see how we can take advantage of these methods and keep the same highly available, high performance and very easy to use persistent data platform for your application.
In the last post I mentioned there are resources that have already gone through that do a better job than me in helping you understand containers and Kubernetes.
So if you are a virtualization admin like me and want to make 2018 the year you know enough to be dangerous I suggest the following resources.
Do Nigel Poulton’s Docker Deep Dive. A foundational understanding to containers will help the orchestration parts make sense.https://app.pluralsight.com/library/
Do Kubernetes the Hard Way. Once you see this the options that make K8s easier will seem a lot cooler and you will understand what they do in the background.
Start thinking: Does this app need a VM or a container? Once you are asking the question you will begin to think critically about the choices.
I am not sure we all need to move 100% off of VM’s today. Starting to ask the questions will help prepare us to provide these services to our customers when the workloads and workflows that require them to arise.