OpenStack administrators have to deal with a lot, including, potentially, many different storage backends in Cinder. Pure Storage now make it easier for them to see what is going on with their Pure FlashArray backends.
With so many different storage backends available to OpenStack Cinder administrators who want to understand how their Cinder backends are being utilized have, historically, had to log on to every backend and therefore need to be conversant with all the vendor-specific storage frontends they have in their environment. The OpenStack Horizon GUI is complex enough, without having to learn other GUIs.
Additionally, OpenStack tenants who are interested in their storage utilization and performance have no way of getting this information without raising internal tickets for their storage support teams – and we all know how long those can take to get answered…
Well, Pure Storage has tried to alleviate these problems by providing an OpenStack plugin for Horizon.
From an OpenStack administrators perspective give a high level view of the utilization levels of Pure Storage FlashArrays configured as Cinder backends, and the tenants it will provide real-time volume utilization and performance information.
So what do you get with the plugin?
For the Administrator, there is a new Horizon panel in the Admin / System section called Pure Storage.
In this new panel you get a simple view of your FlashArray backends in the well-known Horizon format. Interesting information such as overall data reduction rates (with and without thin-provisioning included) is given as well as utilization levels against array limits – useful to see for both OpenStack dedicated arrays and those that have multiple workloads.
If you select the actual array name in the table a new browser tab will open at the actual FlashArray GUI if you want to log in directly, however if you select the Cinder Name in the table you get a detailed view of the array in Horizon providing more capacity and performance information.
The Overview pie charts in this detailed view show the array specific limits for this array, so will be different depending on the Purity version of the FlashArray.
If you aren’t an Administrator and just a regular Tenant in OpenStack, you won’t see these options available to you, but you will be able to get more detail on any volumes are using that are backed by Pure Storage FlashArrays.
By selecting a Pure backed volume in your Volumes page you will get enhanced detail information around the utilization, data reduction and performance of your volume. This data is current, so a refresh of the page will update these statistics.
Hopefully, OpenStack Admins and Users will find this new Horizon plugin useful.
To get more details on installing and configuring check out this GitHub repo.
In this, the final part of a 3-part series, I cover the latest developments in ephemeral storage. Part 1 covered traditional ephemeral storage and Part 2 covered persistent storage.
CSI Ephemeral Storage
With the release of Kubernetes 1.15, there came the ability for CSI drivers that support this feature, the ability to create ephemeral storage for pods using storage provisioned from external storage platforms. Within 1.15 a feature gate needed to be enabled to allow this functionality, but with 1.16 and the beta release of this feature, the feature gate defaulted to true.
Conceptually CSI ephemeral volumes are the same as emptyDir volumes that were discussed above, in that the storage is managed locally on each node and is created together with other local resources after a Pod has been scheduled onto a node. It is required that volume creation has to be unlikely to fail, otherwise, the pod gets stuck at startup.
These types of ephemeral volumes are currently not covered by the storage resource usage limits of a Pod, because that is something that kubelet can only enforce for storage that it manages itself and not something provisioned by a CSI provisioner. Additionally, they do not support any of the advanced features that the CSI driver might provide for persistent volumes, such as snapshots or clones.
To identify if an installed CSI supports ephemeral volumes just run the following command and check supported modes:
# kubectl get csidriver
NAME ATTACHREQUIRED PODINFOONMOUNT MODES AGE
pure-csi true true Persistent,Ephemeral 28h
With the release of Pure Service Orchestrator v6.0.4, CSI ephemeral volumes are now supported by both FlashBlade and FlashArray storage.
The following example shows how to create an ephemeral volume that would be included in a pod specification:
This volume is to be 2GiB in size, formatted as xfs and be provided from a FlashArray managed by Pure Service Orchestrator.
Even though these CSI ephemeral volumes are created as real volumes on storage platforms, they are not visible to Kubernetes other than in the description of the pod using them. There are no associated Kubernetes objects and are not persistent volumes and have no associated claims, so these are not visible through the kubectl get pv or kubectl get pvc commands.
When implemented by Pure Storage Orchestrator the name of the actual volume created on either a FlashArray or FlashBlade does not match the PSO naming convention for persistent volumes.
A persistent volume has the naming convention of:
<clusterID>-pvc-<persistent volume uid>
Whereas a CSI ephemeral volumes naming convention is:
For completeness, I thought I would add the next iteration of ephemeral storage that will become available.
With Kubernetes 1.19 the alpha release of Generic Ephemeral Volumes was made available, but you do need to enable a feature gate for this feature to be capable.
These next generation of ephemeral volumes will again be similar to emptyDir volumes but with more flexibility,
It is expected that the typical operations on volumes that are implementing by the driver will be supported, including snapshotting, cloning, resizing, and storage capacity tracking.
Conclusion
I hope this series of posts have been useful and informative.
Storage for Kubernetes has been through many changes over the last few years and this process shows no sign of stopping. More features and functionality are already being discussed in the Storage SIGs and I am excited to see what the future brings to both ephemeral and persistent storage for the containerized world.
In this, the second part of a 3-part series, I cover persistent storage. Part 1 covered traditional ephemeral storage.
Persistent Storage
Persistent storage as the name implies is storage that can maintain the state of the data it holds over the failure and restart of an application, regardless of the worker node on which the application is running. It is also possible with persistent storage to keep the data used or created by an application after the application has been deleted. This is useful if you need to reutilize the data in another application, or as enable the application to restart in the future and still have the latest dataset available. You can also leverage persistent storage to allow for disaster recovery or business continuity copies of the dataset.
StorageClass
A construct in Kubernetes that has to be understood for storage is the StorageClass. A StorageClass provides a way for administrators to describe the “classes” of storage they offer. Different classes might map to quality-of-service levels, or different access rules, or any arbitrary policies determined by the cluster administrators.
Each CSI storage driver will have a unique provisioner that is assigned as an attribute to a storage class and instructs any persistent volumes associated with that storage class to use the named provisioner, or CSI driver when provisioning the underlying volume on the storage platform.
Provisioning
Obtaining persistent storage for a pod is a three-step process:
Define a PersistentVolume (PV), which is the disk space available for use
Define a PersistentVolumeClaim (PVC), which claims usage of part or all of the PersistentVolume disk space
Create a pod that references the PersistentVolumeClaim
In modern-day CSI drivers, the first two steps are usually combined into a single task and this is referred to as dynamic provisioning. Here the PersistentVolumeClaim is 100% if the PersistentVolume and the volume will be formatted with a filesystem on first attachment to a pod.
Manual provisioning can also be used with some CSI drivers to import existing volumes on storage devices into the control of Kubernetes by converting the existing volume into a PersistentVolume. In this case, the existing filesystem on the original volume is kept with all existing data when first mounted to the pod. An extension of this is the ability to import a snapshot of an existing volume, thereby creating a full read-write clone of the source volume the snapshot derived from.
When a PV is created it is assigned a storageClassName attribute and this class name controls many attributes of the PV as mentioned earlier. Note that the storageClassName attribute ensures the use of this volume to only the PVCs that request the equivalent StorageClass. In the case of dynamic provisioning, this is all managed automatically and the application only needs to call the required StorageClass the PVC wants storage from and the volume is created and then bound to a claim.
When the application is complete or is deleted, depending on the way the PV was initially created, the underlying volume construct can either be deleted or retained for use by another application, or a restart of the original application. This is controlled by the reclaimPolicy in the storageClass definition. In dynamic provisioning the normal setting for this is delete, meaning that when the PVC is deleted the associated PV is deleted and the underlying storage volume is also deleted.
By setting the reclaimPolicy to retain this allows for manual reclamation of the PV.
On deletion of the PVC, the associated PV is not deleted and can be reused by another PVC with the same name as the original PVC. This is the only PVC that can access the PV and this concept is used a lot with StatefulSets.
It should be noted that when a PV is retained a subsequent deletion of the PV will result in the underlying storage volume NOT being deleted, so it is essential that a simple way to ensure orphaned volumes do not adversely affect your underlying storage platforms capacity.
At this point, I’d like to mention Pure Service Orchestrator eXplorer which is an Open Source project to provide a single plane of glass for storage and Kubernetes administrator to visualize how Pure Service Orchestrator, the CSI driver provided by Pure Storage, is utilising storage. One of the features of PSOX is its ability to identify orphaned volumes from a Kubernetes cluster.
Persistent Volume Granularity
There are a lot of options available when it comes to how the pod can access the persistent storage volume and these are controlled by Kubernetes. These different options are normally defined with a storageClass.
The most common of these is the accessMode which controls how the data in the PV can be accessed and modified. There are three modes available in Kubernetes:
ReadWriteMany (RWX) – the volume can be mounted as read-write by many nodes
ReadWriteOnce (RWO) – the volume can be mounted as read-write by a single node
ReadOnlyMany (ROX) – the volume can be mounted read-only by many nodes
Additional controls for the underlying storage volume can be provided through the storageClass include mount options, volume expansion, binding mode which is usually used in conjunction with storage topology (also managed through the storageClass).
A storageClass can also apply specific, non-standard, granularity for different features a CSI driver can support.
In the case of Pure Service Orchestrator, all of the above-mentioned options are available to an administrator creating storage classes, plus a number of the non-standard features.
Here is an example of a storageClass definition configured to use Pure Service Orchestrator as the CSI provisioner:
This might look a little complex, but simplistically this example ensures that PersistentVolumes created through this storageClass will have the following attributes:
Quality of Service limits of 10Gb/s bandwidth and 30k IOPs
Volumes are capable of being expended in size
One first use by a pod the volume will be formatted with the xfs filesystem and mounted with the discard flag
The volume will only be created by an underlying FlashArray found in either rack-0 or rack-1 (based on labels defined in the PSO configuration file)
Pure Service Orchestrator even allows the parameters setting to control the NFS ExportRules of PersistentVolumes created on a FlashBlade.
Check back for Part 3of this series, where I’ll discuss the latest developments in ephemeral storage in Kubernetes.
In this series of posts, I’ll cover the difference between ephemeral and persistent storage as far as Kubernetes containers are concerned and discuss the latest developments in ephemeral storage. I’ll also occasionally mention Pure Service Orchestrator™ to show how this can provide storage to your applications do matter what type is required.
Back in the mists of time when Kubernetes and containers, in general, were young storage was only ephemeral. There was no concept of persistency for your storage and the applications running in container environments were inherently ephemeral themselves and therefore there was no need for data persistency.
Initially, with the development of FlexDriver plugins and lately CSI compliant drivers, persistent storage has become a mainstream offering to enable applications that need or require state for their data. Persistent storage will be covered in the second blog in this series.
Ephemeral Storage
Ephemeral storage can come from several different locations, the most popular and simplest being emptyDir. This is, as the name implies, an empty directory mounted in the container that can be accessed by one or more pods in the container. When the container terminates, whether that be cleanly or through a failure event, the mounted emptyDir storage is erased and all its contents are lost forever.
emptyDir
You might wonder where this “storage” used by emptyDir comes from and that is a great question. It can come from one of two places. The most common is actually from the actual physical storage available to the Kubernetes nodes running the container, usually from the root partition. This space is finite and completely dependent on the available free capacity of the disk partition the directory is present on. This partition is also used for lots of other dynamic data, such as container logs, image layers, and container-writable layers, so it is potentially an ever-decreasing resource.
To create this type of ephemeral storage for a pod(s) running in a container, ensure the pod specification has the following section:
volumes:
- name: demo-volume
emptyDir: {}
Note that the {} states that we are not providing any further requirements for the ephemeral volume. The name parameter is required so that pods can mount the emptyDir volume, like this:
volumeMounts:
-mountPath: /demo
name: demo-volume
If multiple pods are running in the container they can all access the same emptyDir if they mount the same volume name.
From the pods perspective, the emptyDir is a real filesystem mapped to the root partition, which is already part utilised, so you will see it in a df command, executed in the pod, as follows (this example has the pod running on a Red Hat CoreOS worker node):
# df -h /demo
Filesystem Size Used Available Use% Mounted on
/dev/mapper/coreos-luks-root-nocrypt
119.5G 28.3G 91.2G 24% /demo
If you want to limit the size of your ephemeral storage this can be achieved by adding resource limits to the container in the pod as follows:
Here the container has requested 2GiB of local ephemeral storage, but the container has a limit of 4GiB of local ephemeral storage.
Note that if you use this method and you exceed the ephemeral-storage limits value the Kubernetes eviction manager will evict the pod, so this is a very aggressive space limit enforcement method.
emptyDir from RAM
There might be instances that you only need a minimal scratch space area for your emptyDir and you don’t want to use any of the root partition. In this case, resources permitting, you can create this in RAM. The only difference in the creation of the emptyDir is that more information is passed during its creation in the pod specification as follows:
In this case, the default size of the mounted directory is half of the RAM the running node has and is mounted on tmpfs. For example, here the worker node has just under 32GB of RAM and therefore the emptyDir is 15.7GB, about half:
# df -h /demo
Filesystem Size Used Available Use% Mounted on
tmpfs 15.7G 0 15.7G 0% /demo
You can use the concept of sizeLimit for the RAM-based emptyDir but this does not work as you would expect (at the time of writing). In this case, the sizeLimit is used by the Kubernetes eviction manager to evict any pods that exceed the sizeLimit specified in the emptyDir.
Check back for Part 2 of this series, where I’ll discuss persistent storage in Kubernetes.
In this post, I’m going to discuss how to load balance your storage provisioning across a fleet of Pure Storage FlashArrays.
As an integral part of Pure’s Kubernetes integration, Pure Service Orchestrator has the ability to load balance across a fleet of Pure storage devices. This is great for your containerized space, but I wondered how you could do something similar for arrays in a non-containerized environment. For example, a vSphere environment where there are multiple Pure Storage FlashArrays available to a vCenter and when creating a new datastore, you want to do this on the least full array.
What I wanted to do was orchestrate which storage array a volume was provisioned on automatically without the storage administrator having to keep checking which array to use. Now, when I think of automation and orchestration I immediately think of Ansible.
Pure Storage has an amazing suite of modules for Ansible that we can leverage to do this work, so I created an Ansible load-balancing role called, logically enough, lb.
The role takes a list of arrays, interrogate them and works out which has the least used capacity and then provide the information required for the rest of the playbook to provision against that array.
So where can you find this role and how do you use it?
The role can be found on the Pure Storage OpenConnect GitHub account in the ansible-playbook-examples repository, under the flasharray/roles directory.
To use it requires you to populate the variables file roles/lb/vars/main.yml with the management IP addresses of your fleet of arrays, together with an API token for a storage admin privilege user for each array. I guess there is no limit to the number of arrays you can load balance over, but the example below is for a fleet of six FlashArrays.
The populated file would look something like this (use your own array credentials):
To use the role just add it into your Ansible playbook.
If you are security-minded, then all of these entries in the URL and API token can be encrypted using Ansible Vault. I wrote another blog post that included details on how to implement Vault for these variable.
When the role has run two variables will have been defined: use_url and use_api. These identify the array with the lowest utilization level and therefore the one you should be provisioning to. There is also an additional variable you can use (use_name) that identifies the true name of the array selected.
A super simple playbook that uses the lb role and then provisions a single volume to the least full array is shown here:
- name: Pure Storage load balancing example
hosts: localhost
gather_facts: no
vars:
array_usage: [] # Do not remove - required by the role
roles:
- role: lb
tasks:
- name: Provisioning to {{ use_name }}
purefa_volume:
fa_url: "{{ use_url }}"
api_token: "{{ use_api }}"
name: lb_test
size: 50G
I hope this short post and this role prove useful, and if you have any of your own roles or playbooks for Pure Storage devices that you think would be useful to other users, please feel free to contribute them to the ansible-playbook-examples GitHub repository.
How to Upgrade your PSO FlexDriver deployment to the latest CSI-based driver
Smart Provisioning with PSO
Over the past few months, the Kubernetes FlexDriver codebase has been deprecated and there is a solid shift towards using CSI-based drivers for providing Persistent Volumes to Kubernetes environments.
I’m not going to address the reasons behind that shift here, but suffice to say that all the major storage providers are now using the CSI specification for their persistent storage drivers in Kubernetes.
This is great, but what about those early adopters who installed FlexDriver based drivers?
It’s not the easiest thing to migrate the control of a persistent volume from one driver to another, in fact, it is practically impossible unless you are a Pure Storage customer and are using PSO.
With the latest release of PSO, ie 5.2.0, there is now a way to migrate your PSO FlexDriver created volumes under the control of the PSO CSI driver.
It’s still not simple and it’s a little time consuming, and you do need an outage for your application, but it is possible.
Simply (sic), these are the steps you need to undertake to perform your migration:
Scale down your applications so that no pods are using the FlexDriver managed PVCs and PVs.
Uninstall your FlexDriver – don’t worry all your PVs and PVCs will remain and the applications using them won’t notice.
Install the CSI based driver – now all new PVs will be managed by this new driver.
Identify your PVs that were created by the FlexDriver.
Patch the PV definition to ensure it doesn’t get automatically deleted by Kubernetes.
Delete the PVC and then the PV – sounds scary, but the previous patch command means that underlying volume on the backend storage is retained
Import the storage volume back into Kubernetes and under the CSI drivers control – this is where you need PSO v5.2.0 or higher…
Scale back up your applications.
Well that was easy, wasn’t it?
More details on exactly how to perform the steps above are detailed in the PSO GitHub repository documentation.
Now, you may feel a little paranoid about these deletion commands you are running against your precious data, so as a “belt and braces” type activity, you could always make a clone or a snapshot of your underlying storage volumes on your array before you do step 6. But remember to delete these clones when you have completed the migration.
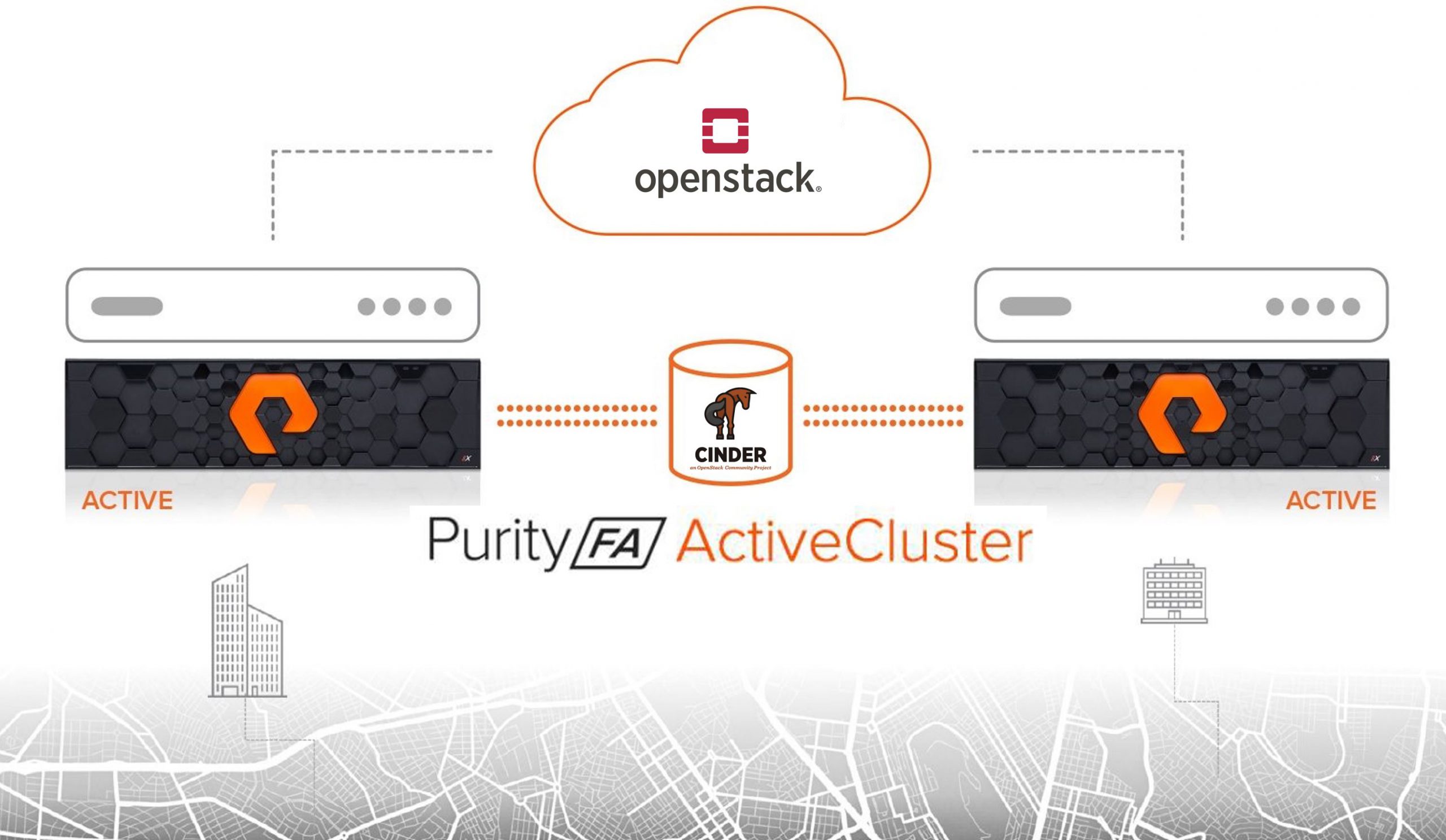
Since the Mitaka release of OpenStack, the Pure Storage Cinder driver has supported Cinder replication, although this first iteration only supported asynchronous replication.
The Rocky release of OpenStack saw Pure’s Cinder driver support synchronous replication by integrating our ActiveCluster feature from the FlashArray.
This synchronous replication automatically created an ActiveCluster pod on the paired FlashArrays called cinder-pod. A pretty obvious name I would say.
While this provided a seamless integration for OpenStack users to create a synchronously replicated volume using a correctly configured volume type, there was one small limitation. ActiveCluster pods were limited to 3000 volumes.
Now you might think that is more than enough volumes for any single ActiveCluster environment. I certainly did until I received a request to be able to support 6000 volumes synchronously replicated.
After some scratching of my head, I remembered that from the OpenStack Stein release of the Pure Cinder driver there is an undocumented (well, not very well documented) parameter that allows the name of the ActiveCluster pod to be customizable and that gave me an idea….
Can you configure Cinder to use the same backend as separate stanzas in the Cinder config file with different parameters?
It turns out the answer is Yes.
So, here’s how to enable your Pure FlashArray Cinder driver to use a single ActiveCluster pair of FlashArrays to allow for 6000 synchronously replicated volumes.
First, we need to edit the cinder.conf file and create two different stanzas for the same array that is configured in an ActiveCluster pair and ensure we have enabled both of these backends:
If we look at the two stanzas, the only difference is that the pure_replication_pod_name is different. I have also set the volume_backend_name to be the same for both configurations. There is a reason for this I will cover later.
After altering the configuration file, make sure to restart your Cinder Volume service to implement the changes.
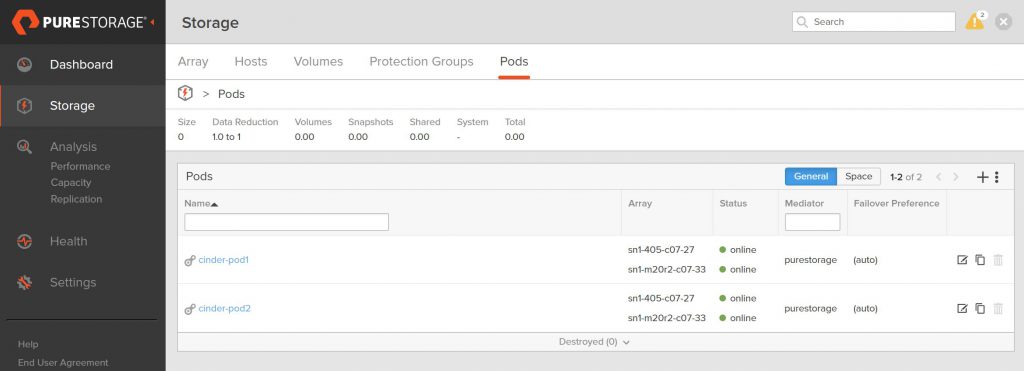
After restarting the cinder-volume service, you will see on the FlashArray that two ActiveCluster pods now exist with the names defined in the configuration file.
This is the first step.
Now we need to enable volume types to be able to use these pods and also to load-balance across the two pods – why load-balance? It just seems to make more sense to make volumes evenly utilize the pods, but there is no specific reason for doing this. If you wanted to use each pod separately, then you would need to set a different volume_backend_name in the Cinder configuration file for each array stanza.
When creating a volume type to use synchronous replication you need to set some specific extra_specs in the type definition. These are the commands to use:
openstack volume type create pure-repl
openstack volume type set --property replication_type=’<in> sync’ pure_repl
openstack volume type set --property replication_enabled=’<is> True’ pure_repl
openstack volume type set --property volume_backend_name=’pure’ pure_repl
The final configuration of the volume type would now look something like this:
openstack volume type show pure-repl
+--------------------+-------------------------------------------------------------------------------------------+
| Field | Value |
+--------------------+-------------------------------------------------------------------------------------------+
| access_project_ids | None |
| description | None |
| id | 2b6fe658-5bbf-405c-a0b6-c9ac23801617 |
| is_public | True |
| name | pure-repl |
| properties | replication_enabled='<is> True', replication_type='<in> sync', volume_backend_name='pure' |
| qos_specs_id | None |
+--------------------+-------------------------------------------------------------------------------------------+
Now, all we need to do is use the volume type when creating
our Cinder volumes.
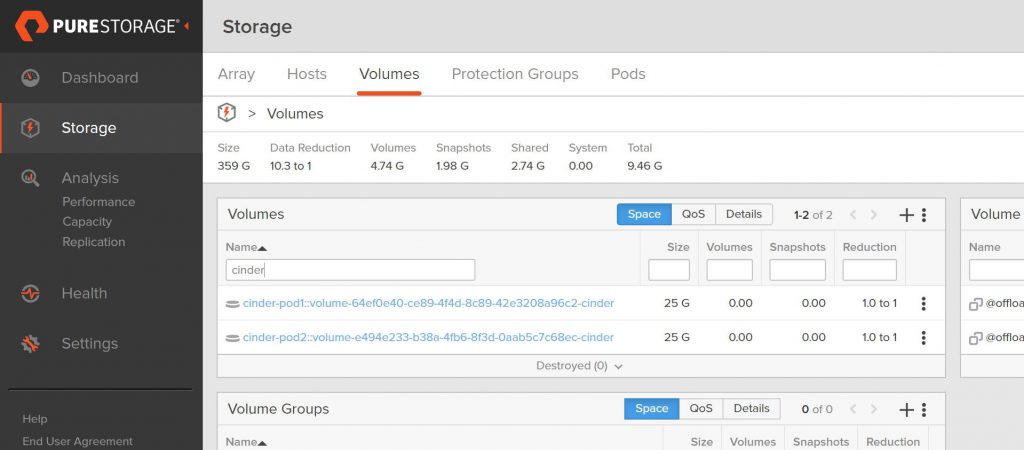
Let’s create two volumes and see how they appear on the FlashArray:
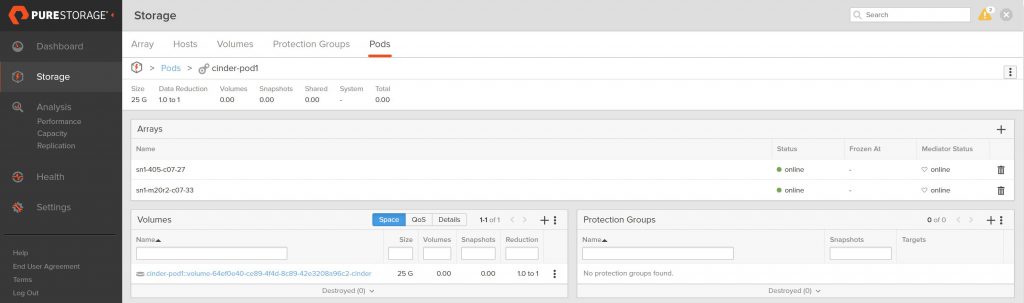
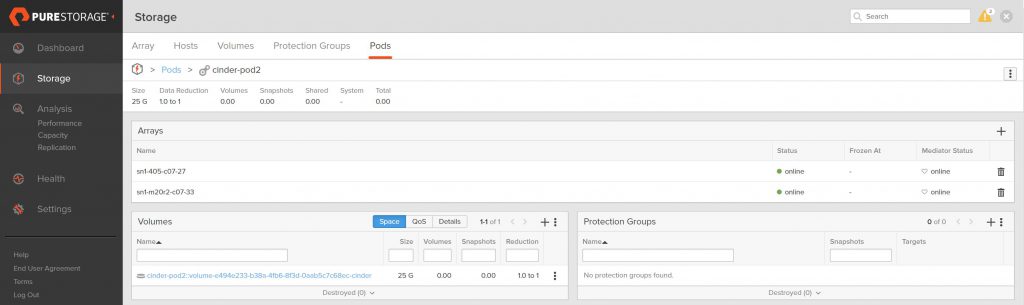
Looking at the FlashArray, we can see the two volumes we just created (I am filtering the volume name on cinder just so you only see the OpenStack related volumes on this array)
The volume naming convention we use at Pure shows that these
volumes are in a pod due to the double colon (::)
in the name and the pod name for each volume is cinder-pod1
and cinder-pod2 respectively.
The view of each pod also shows only one volume in each.
If you didn’t want to load-balance across the pods and needed the flexibility to specify the pod a volume exists in, all I need do is set the volume_backend_name to be different in the configuration file array stanzas and then create two volume types. Each would point to the different volume_backend_name setting.
Please welcome Simon making a guest appearance to go through whatever it is this is about. 🙂 – Jon
Got to love those TLAs!!
To demystify the title of this blog, this will be about installing Pure Service Orchestrator (PSO) with Docker Kubernetes Service (DKS).
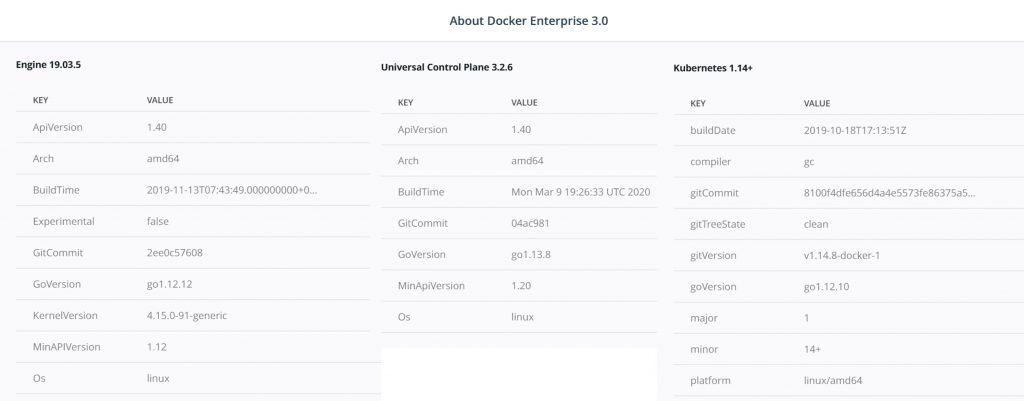
Specifically, I’ll be talking about PSO CSI driver v5.0.8, running with Docker EE 3.0 and the Universal Control Plane (UCP) 3.2.6, managing Kubernetes 1.14.8.
Let’s assume you have Docker Enterprise 3.0 installed on 3
Linux nodes, in my case they are running Ubuntu 18.04. You decide you want them to all run the Docker
Kubernetes Service (DKS) and have any persistent storage provided by your Pure
Storage FlashArray or FlashBlade – how do you go about installing all of these
and configuring them?
Pre-Requisites
As we are going to be using PSO with Pure Storage array for
the persistent storage, ensure that all nodes that will part of DKS have the
following software installed:
nfs-common
multipath-tools
Install UCP
The first step to getting your DKS environment up is to
install the Docker Universal Control Plane (UCP) from the node you will be
using as your master.
As PSO supports CSI snapshots, you will want to ensure that
when installing UCP, you tell it to open the Kubernetes feature gates, thereby
enabling persistent volumes snapshots through PSO.
If you don’t want to open the feature gates, don’t use the --storage-expt-enabled switch in the install command.
Answer the questions the install asks, wait a few minutes,
and voila you have Docker UCP installed and can access it through its GUI at http://<host IP>. Note that you
may be prompted to enter your Docker EE license key on the first login.
When complete you will have a basic, single node, environment consisting of docker EE 3.0, UCP 3.2.6 and Kubernetes 1.14.8.
Add Nodes to Cluster
Once you have your master node up and running, you can add
your two worker nodes to the cluster.
The first step is to ensure your default scheduler is
Kubernetes, not Swarm. If you don’t set this pods will not run on the worker
nodes due to taints that are applied.
Navigate to your username in the left pane and select Admin
Settings and then Scheduler. Set the default Orchestrator type to
Kubernetes and save your change
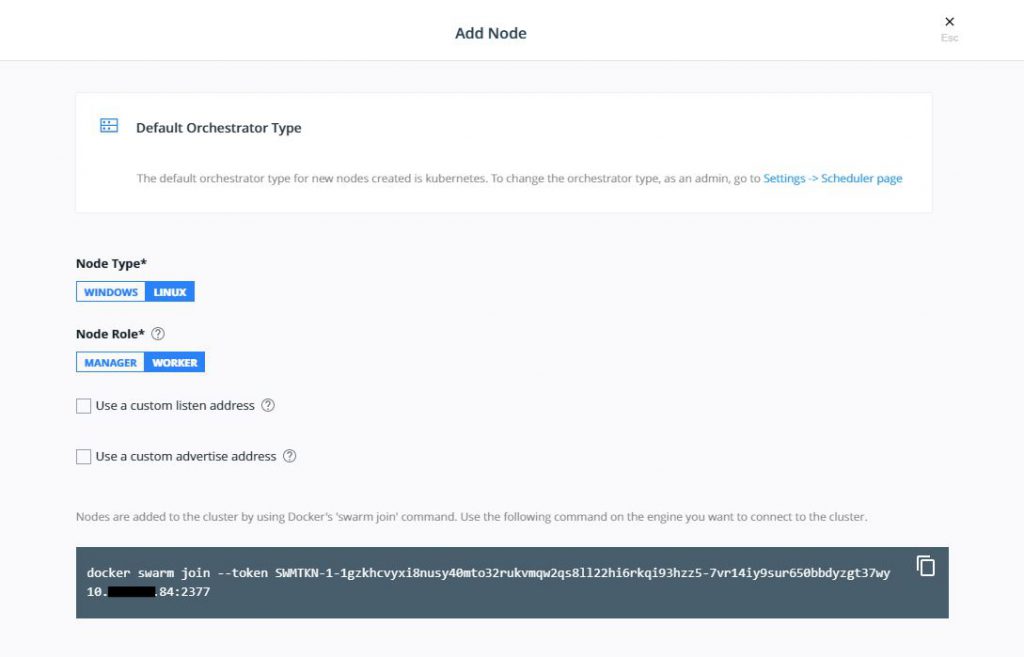
Now to add nodes navigate to Shared Resources and
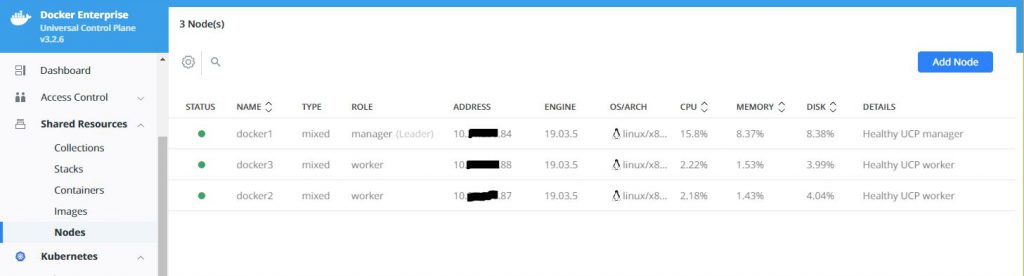
select Nodes and then Add Nodes. You will see something like
this:
Use the command on each worker node to get them to join the
Kubernetes cluster. When complete, your nodes should be correctly joined and
look like this is your Nodes display.
You now have a fully functioning Kubernetes cluster managed
by Docker UCP.
Get your client ready
Before you can install PSO you need to install a Docker
Client Bundle onto your local node that will be used to communicate with your
cluster. I use a Windows 10 laptop, but run the Ubuntu shell provided by
Windows to do this.
To get the bundle, navigate to your user profile, select Client
Bundles and then Generate Client Bundle from the dropdown menu.
Unzip the tar file you get into your working directory.
Next, you need to get the correct kubectl version, which
with UCP 3.2.6 is 1.14.8, by running the following commands:
Check your installation by running the following commands:
# kubectl version
Client Version: version.Info{Major:"1", Minor:"14", GitVersion:"v1.14.8", GitCommit:"211047e9a1922595eaa3a1127ed365e9299a6c23", GitTreeState:"clean", BuildDate:"2019-10-15T12:11:03Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"14+", GitVersion:"v1.14.8-docker-1", GitCommit:"8100f4dfe656d4a4e5573fe86375a5324771ec6b", GitTreeState:"clean", BuildDate:"2019-10-18T17:13:51Z", GoVersion:"go1.12.10", Compiler:"gc", Platform:"linux/amd64"}
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
docker1 Ready master 24h v1.14.8-docker-1
docker2 Ready <none> 24h v1.14.8-docker-1
docker3 Ready <none> 24h v1.14.8-docker-1
Now we are nearly ready to install PSO, but PSO requires Helm, so now we install Helm3 (I’m using v3.1.2 here, but check for newer versions) and validate:
# wget https://get.helm.sh/helm-v3.1.2-linux-amd64.tar.gz
# tar -zxvf helm-v3.1.2-linux-amd64.tar.gz
# mv linux-amd64/helm /usr/bin/helm
# helm version
version.BuildInfo{Version:"v3.1.2", GitCommit:"d878d4d45863e42fd5cff6743294a11d28a9abce", GitTreeState:"clean", GoVersion:"go1.13.8"}
And finally…
We are ready to install PSO.. Here we are just going to
follow the instructions in the PSO GitHub repo, so check in their for updates
if you are reading this in my future…
# helm repo add pure https://purestorage.github.io/helm-charts
# helm repo update
So the latest version at this time is 5.0.8, so we should
get the values.yaml
configuration file that matches this version…
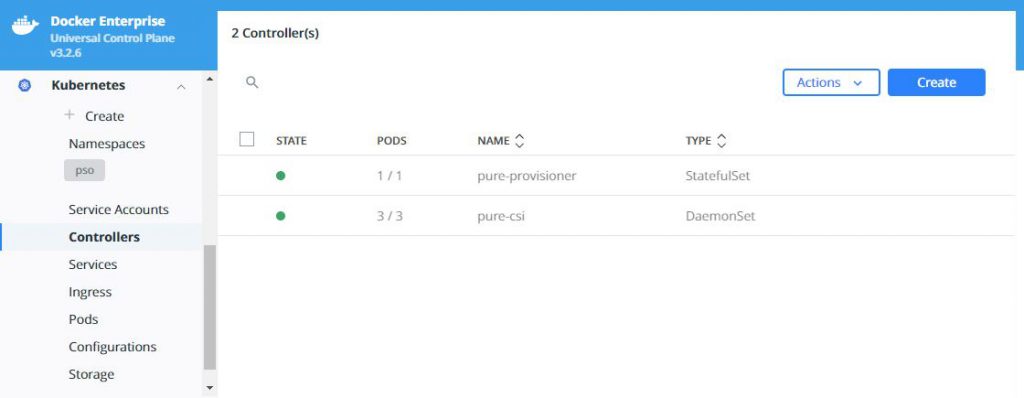
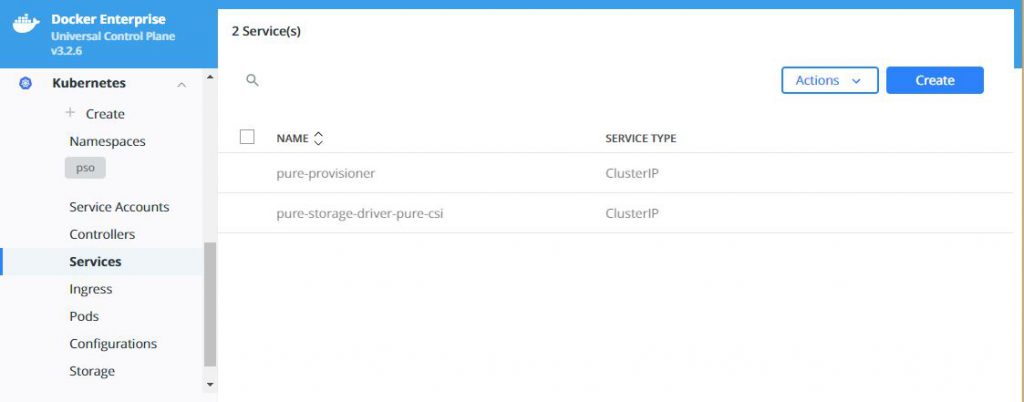
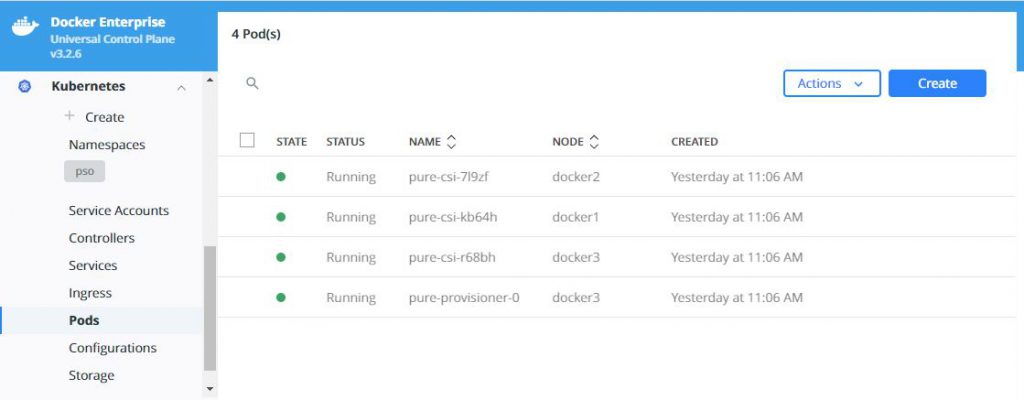
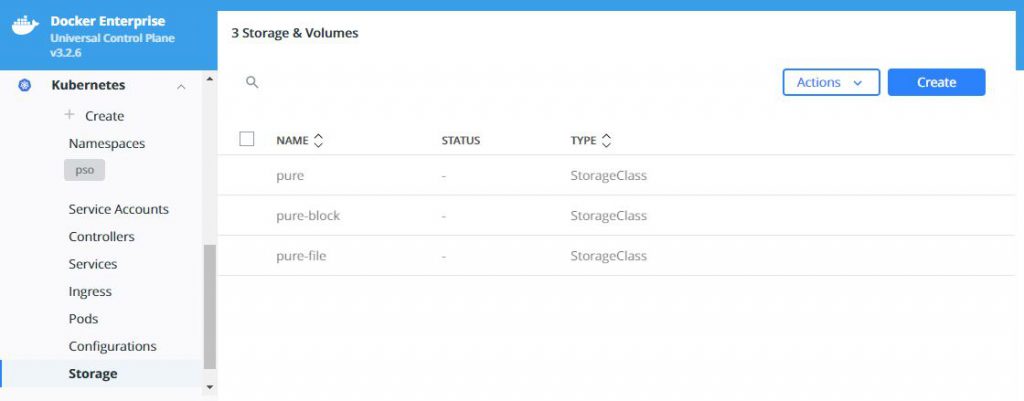
What does this look like in Docker UCP you ask, well this is
what you will see in various screens:
Now you can start using PSO to provide your persistent
storage to your containerized applications, and if you enabled the
feature-gates as suggested at the start of this blog, you could also take
snapshots of your PVs and restore these to new volumes. For details on exactly
how to do this read this: https://github.com/purestorage/helm-charts/blob/5.0.8/docs/csi-snapshot-clones.md,
but make sure you install the VolumeSnapshotClass first wit this command:
The version of Kubernetes provided in Docker UCP 3.2.6 does not support volume
cloning, but future releases may enable this functionality – check with Docker
UCP and Docker EE release notes.