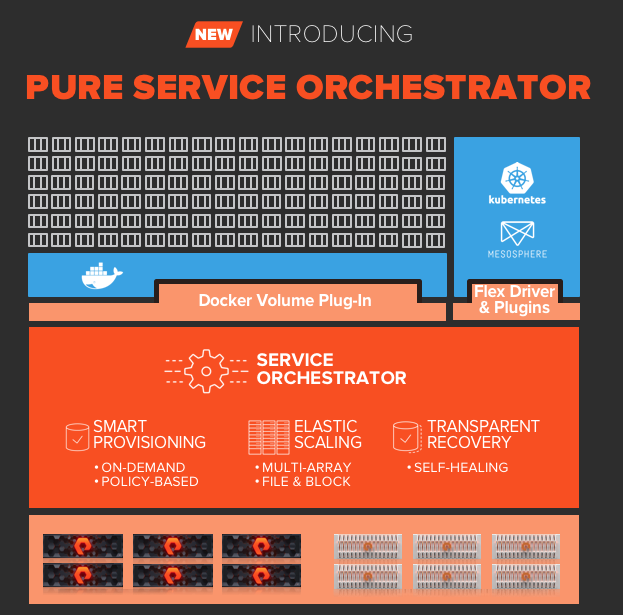
Last week Portworx 2.8 went GA, with it new support for Tanzu TKGs TKGm (We supported PKS/TKGi for a long time), but also Support for Cloud Drives for FlashArray and Direct Access for FlashBlade. It also simplified the installation of Portworx with Tanzu from this earlier version.

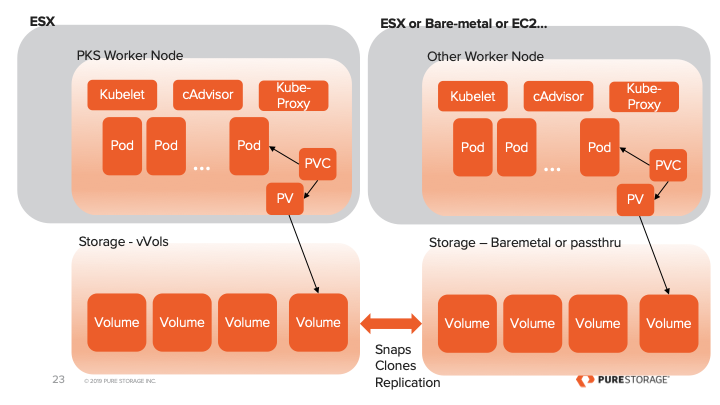
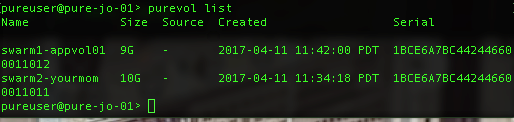
Portworx will automate creating a storage pool from volumes provisioned from the FlashArray. This is done for your during the install, you may specify the size of the volumes in the spec generator at https://central.portworx.com
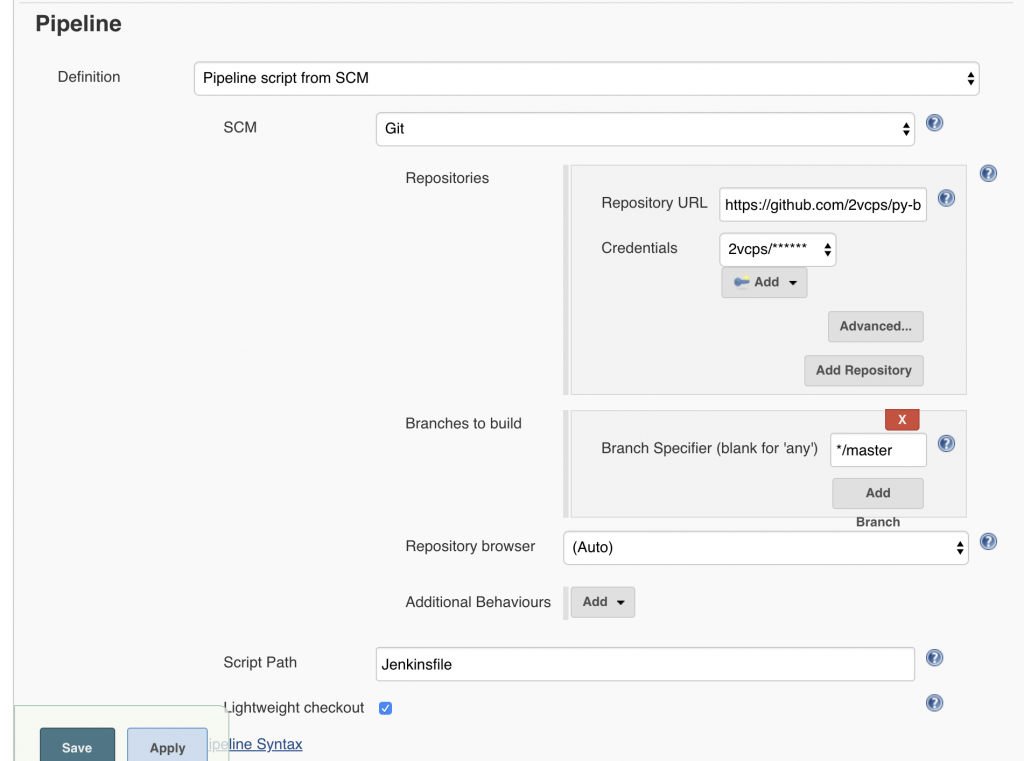
Process to install
NOTE as of 8/4/21: This feature is in Tech Preview (contact me if you want to run in Production)
- Create the px-pure-secret from the pure.json file
- Generate your Portworx Cluster spec from https://central.portworx.com
- Install the PX-Operator (command at the end of the spec generator).
- Install the Portworx Storage Cluster
- https://docs.portworx.com/reference/pure-json-reference/
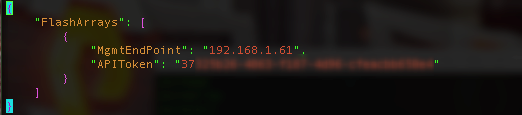
Also look that the pure.json reference in order to get the API key and token in a secret for you to use with Portworx. The installation of Portworx detects this Kubernetes secret and uses that information to provision drives from the array.
Check out the youtube demo:
Sample pure.json
{
"FlashArrays": [
{
"MgmtEndPoint": "<first-fa-management-endpoint>",
"APIToken": "<first-fa-api-token>"
},
{
"MgmtEndPoint": "<second-fa-management-endpoint>",
"APIToken": "<second-fa-api-token>"
}
],
"FlashBlades": [
{
"MgmtEndPoint": "<fb-management-endpoint>",
"APIToken": "<fb-api-token>",
"NFSEndPoint": "<fb-nfs-endpoint>",
},
{
"MgmtEndPoint": "<fb-management-endpoint>",
"APIToken": "<fb-api-token>",
"NFSEndPoint": "<fb-nfs-endpoint>",
}
]
}kubectl create secret generic px-pure-secret --namespace kube-system --from-file=pure.jsonRemember the secret must be called px-pure-secret and be in the namespace that you install Portworx.

2. Generate the spec for the Portworx Cluster.
3. Install the PX-Operator – I suggest using what you get from the Spec generator online or down to a local file.
kubectl apply -f pxoperator.yaml4. Install the Storage Cluster
kubectl apply -f px-spec.yamlFor FlashBlade!
Also included in the pure.json is the API Token and IP information for my FlashBlade. Since the FlashBlade runs NFS the K8s node mounts it directly. We call with Direct Attach and allows you to leverage your FlashBlade for data that may exist outside of the PX-Cluster. Watch the demo to see it in action. Create a StorageClass for FlashBlade and a PVC using that class. Portworx automates the rest.
More info:
https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/create-pvcs/pure-flashblade/

Links
https://docs.portworx.com/cloud-references/auto-disk-provisioning/pure-flash-array/
https://docs.portworx.com/reference/pure-json-reference/
https://docs.portworx.com/portworx-install-with-kubernetes/storage-operations/create-pvcs/pure-flashblade/