One of the great new features of PSO 6 is ability to create a storage class with a pre-defined limit on IO or bandwidth (or both). Watch the following short demo to check it out.
Now if you used any of the old versions of PSO you know it can smart provision across Pure Storage arrays with a single storageClass for block and one for file. Today I am proud to share the mysterious and sometimes confusing third storageClass pure is no longer installed with PSO 6. The long story is that storage class was to support legacy systems that use the 1.0 version of our driver. There has been 2.5 years to get used to pure-block. So now with the upgrade you can make the right choice.
jowings@asgard ~/pso-values k get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
pure-block pure-csi Delete Immediate true 56s
pure-file pure-csi Delete Immediate true 56s
Coming July 14 at 12 EST or 9am PST there will be a combined Kasten and Pure webinar about Kubernetes backup and mobility. As you are working on providing the expected levels of enterprise grade backup and recovery for you k8s based applications this will be a great webinar to help you learn more about what you can use to fill those requirements. Register here:
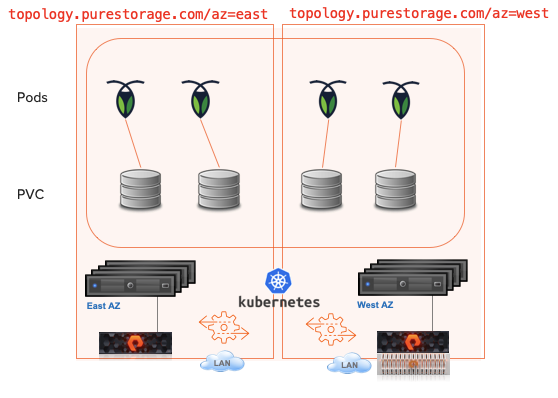
TL;DR – Move Kubernetes volumes from legacy storage to Pure Storage.
So you have an amazing new Pure Storage array in the datacenter or in public cloud. The Container Storage Interface doesn’t provide a built in way to migrate data between backend devices. I previously blogged about a few ways to clone and migrate data between clusters but the data has to already be located on a Pure FlashArray.
Lately, Pure has been working with a new partner Kasten. While more is yet to come. Check out this demo (just 5:30) and see just how easy it is to move PVC’s while maintaining the config of the rest of the k8s application.
Demo EBS to CBS (this could be used to migrate off other devices too)
This demo used EKS in AWS for the Kubernetes cluster.
Application initially installed using a PVC for MySQL on EBS.
Kasten is used to backup the entire state of the app with the PVC to S3. This target could be a FlashBlade in your datacenter.
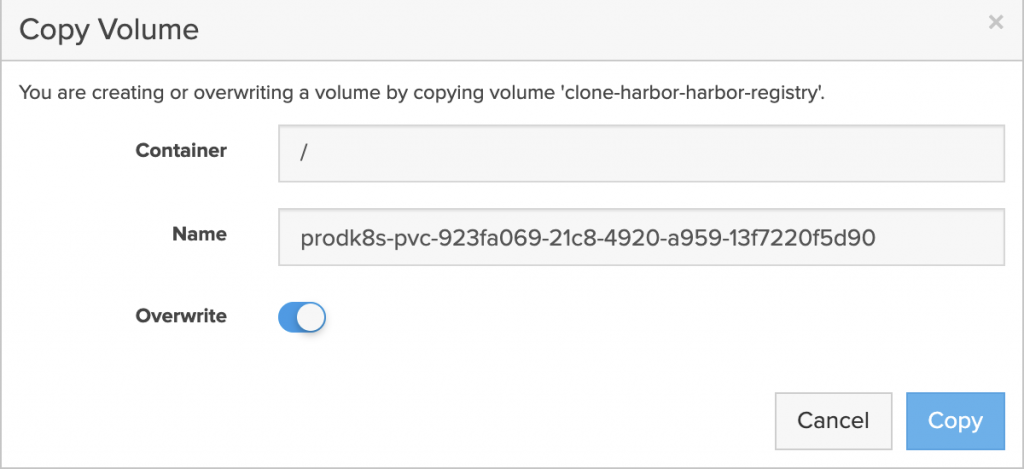
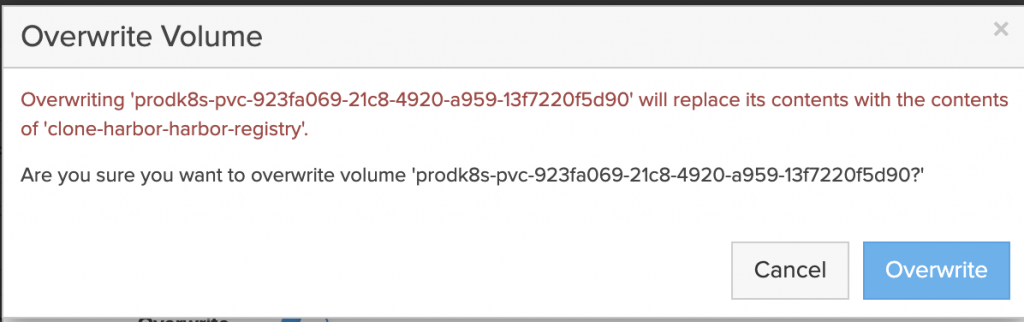
The application is restored to the same namespace but a Kasten Transform is used to convert the PVC to the “pure-block” StorageClass.
Application is live and using PSO for the storage on Cloud Block Store.
Why
Like the book says, “End with why”. Ok maybe it doesn’t actually say that. Let’s answer the “why should I do this?”
First: Why move EBS to CBS This PVC is 10GB on EBS. At this point in time it consumes about 30MB. How much does the AWS bill on the 10GB EBS volume? 10GB. On Cloud Block Store this data is reduced (compressed and deduped) and thin provisioned. How much is on the CBS? 3MB in this case. Does this make sense for 1 or 2 volumes? Nope. If your CIO has stated “move it all to the cloud!” This can be a significant savings on overall storage cost.
Second: Why move from (some other thing) to Pure? I am biased to PSO for Kubernetes so I will start there and then give a few bullets of why Pure, but this isn’t the sales pitch blog. Pure Service Orchestrator allows you a simple single line to install and begin getting storage on demand for your container clusters. One customer says, “It just works, we kind of forget it is there.” and another commented, “I want 100GB of storage for my app, and everything else is automated for me.”
Why Pure?
Efficiency – Get more out of the all-flash, higher dedupe with no performance penalty does matter.
Availability – 6×9’s uptime measured across our customer base, not an array in a validation lab. Actual customers love us.
TL;DR – EBS Volumes fail to mount when multipathd is installed on EKS worker nodes.
EKS and PSO Go Great together!
AWS Elastic Kubernetes Service is a great way to dive in with managed Kubernetes in the cloud. Pure Service Orchestrator integrates EKS worker nodes into the Cloud Block Store on AWS. I created this ansible playbook to make sure the right packages and services are started on my worker nodes.
In my previous testing with PSO and EKS I was basically focused on using PSO only. Recently the use case of migrating from EBS to CBS has shown to be pretty valuable to our customers in the cloud. To create the demo I used an app I often use for demoing PSO. It is 2 Web server containers attached to a mySQL container with a persistent volume. Very easy. I noticed though as I was using the built in gp2 Storage Class it started behaving super odd after I installed PSO. I installed the AWS EBS CSI driver. Same thing. It could not mount volumes or snapshot them in EBS. PSO volumes on CBS worked just fine. I figure most customers don’t want me to break EBS.
After digging around the internet and random old Github issues there was no one thing seemingly having the same issue. People were having problems that had like 1 of the 4 symptoms. I decided to test when in my process it broke after I enabled the package device-mapper-multipath. So it wasn’t PSO as much as a very important pre-requisite to PSO causing the issue. What it came down to is the EBS volumes were getting grabbed by multipathd and the Storage Class didn’t know how to handle the different device names. So I had to find how to use multipathd for just the Pure volumes. The right settings in multipath.conf solved this. This is what I used as an example:
I am telling multipathd to ignore everything BUT Pure. This solved my issue. So I saved this into the local directory and added the section in the ansible playbook to copy that file to each worker node in EKS. 1. Copy the ansible playbook above to a file prereqs.yaml 2. Copy the above multipath blacklist settings to multipath.conf and save to the same directory as prereqs.yaml 3. Run the ansible playbook as shown below. (make sure the inventory.ini has IP’s and you have the SSH key to login to each worker node.
# Make sure inventory.ini has the ssh IP's of each node.
# prereqs.yaml includes the content from above
ansible-playbook -i inventory.ini -b -v prereqs.yaml -u ec2-user
This will install the packages, copy multipath.conf to /etc and restart the services to make sure they pick up the new config.
This morning I needed to upgrade one of my dev clusters to 1.17.4. I decided to capture the experience. Don’t worry I speed up the ansible output flying by
I use Kubespray to deploy and upgrade my clusters. I didn’t do anything really to prepare. All of my clusters I can rebuild pretty easy from Terraform if anything breaks.
git clone git@github.com:kubernetes-sigs/kubespray.git
cd kubespray
## Make sure you copy your actual inventory. For more information see the kubespray github repo
ansible-playbook -i inventory/dev/inventory.ini -b -v upgrade-cluster.yaml
Take some time and upgrade
Watch it go for about 40 minutes in my case. Remember this is a dev cluster and the pods I have running can restart all they want. I don’ t care. Everything upgrades through the first part of the video. Now lets upgrade Pure Service Orchestrator.
Now if you watch the video you will notice I had to add the Pure Storage helm repo. This was a new jump box in the lab. So I had PSO installed just not from this actual host. It is easy to add. More details are in the Pure Helm Chart README.
I build and destroy Kubernetes clusters nearly weekly. Doing it on VMs makes this super easy. I also need to demo Pure Service Orchestrator so having in guest iSCSI is a must. Following this repo should give any vSphere admin an easy way to learn kubectl, helm and PSO quite easily (of course PSO works with Pure FlashArray and FlashBlade). This uses Terraform to create the VM and Kubespray to install k8s. Ansible can also be used for a few automations of package installs and updates.
I am going to try something new and not recreate the github readme and just share the repo link.