In this, the final part of a 3-part series, I cover the latest developments in ephemeral storage. Part 1 covered traditional ephemeral storage and Part 2 covered persistent storage.
CSI Ephemeral Storage
With the release of Kubernetes 1.15, there came the ability for CSI drivers that support this feature, the ability to create ephemeral storage for pods using storage provisioned from external storage platforms. Within 1.15 a feature gate needed to be enabled to allow this functionality, but with 1.16 and the beta release of this feature, the feature gate defaulted to true.
Conceptually CSI ephemeral volumes are the same as emptyDir volumes that were discussed above, in that the storage is managed locally on each node and is created together with other local resources after a Pod has been scheduled onto a node. It is required that volume creation has to be unlikely to fail, otherwise, the pod gets stuck at startup.
These types of ephemeral volumes are currently not covered by the storage resource usage limits of a Pod, because that is something that kubelet can only enforce for storage that it manages itself and not something provisioned by a CSI provisioner. Additionally, they do not support any of the advanced features that the CSI driver might provide for persistent volumes, such as snapshots or clones.
To identify if an installed CSI supports ephemeral volumes just run the following command and check supported modes:
# kubectl get csidriver
NAME ATTACHREQUIRED PODINFOONMOUNT MODES AGE
pure-csi true true Persistent,Ephemeral 28h
With the release of Pure Service Orchestrator v6.0.4, CSI ephemeral volumes are now supported by both FlashBlade and FlashArray storage.
The following example shows how to create an ephemeral volume that would be included in a pod specification:
volumes: - name: pure-vol csi: driver: pure-csi fsType: xfs volumeAttributes: backend: block size: "2Gi"
This volume is to be 2GiB in size, formatted as xfs and be provided from a FlashArray managed by Pure Service Orchestrator.
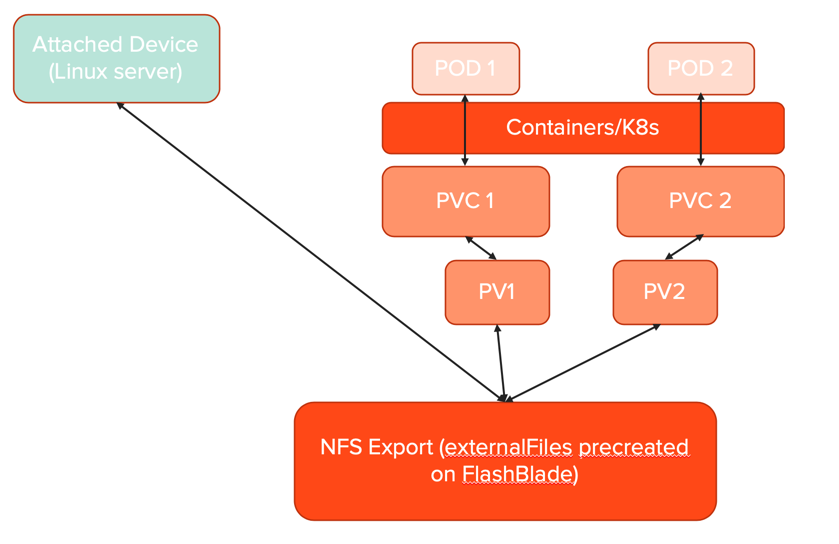
Even though these CSI ephemeral volumes are created as real volumes on storage platforms, they are not visible to Kubernetes other than in the description of the pod using them. There are no associated Kubernetes objects and are not persistent volumes and have no associated claims, so these are not visible through the kubectl get pv or kubectl get pvc commands.
When implemented by Pure Storage Orchestrator the name of the actual volume created on either a FlashArray or FlashBlade does not match the PSO naming convention for persistent volumes.
A persistent volume has the naming convention of:
<clusterID>-pvc-<persistent volume uid>
Whereas a CSI ephemeral volumes naming convention is:
<clusterID>-<namespace>-<podname>-<unique numeric identifier>
Generic Ephemeral Storage
For completeness, I thought I would add the next iteration of ephemeral storage that will become available.
With Kubernetes 1.19 the alpha release of Generic Ephemeral Volumes was made available, but you do need to enable a feature gate for this feature to be capable.
These next generation of ephemeral volumes will again be similar to emptyDir volumes but with more flexibility,
It is expected that the typical operations on volumes that are implementing by the driver will be supported, including snapshotting, cloning, resizing, and storage capacity tracking.
Conclusion
I hope this series of posts have been useful and informative.
Storage for Kubernetes has been through many changes over the last few years and this process shows no sign of stopping. More features and functionality are already being discussed in the Storage SIGs and I am excited to see what the future brings to both ephemeral and persistent storage for the containerized world.