Kubecon and VMware Explore are coming up. One of our most popular sessions from our VMware Explore(and VMworld) is the Stretched Cluster for VMware/vVols. Now, you all may notice that SRM and other DR solutions do not work with Tanzu, but I want all of you to know that PX-DR Sync or Metro-DR is supported for Tanzu. This allows you to have ZERO RPO when failing Stateful workloads from 1 cluster to another. This can be from one vSphere cluster to another each running TKG.
More information for how to setup Sync-DR with Tanzu can be found here in our docs page.
https://docs.portworx.com/operations/operate-kubernetes/disaster-recovery/px-metro/
Pay close attention to the docs as Tanzu has some special steps in the setup because of the way the Cloud Drives are created and managed with raw CNS volumes.
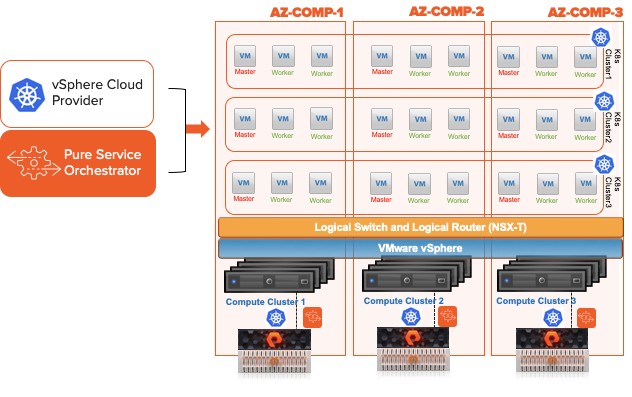
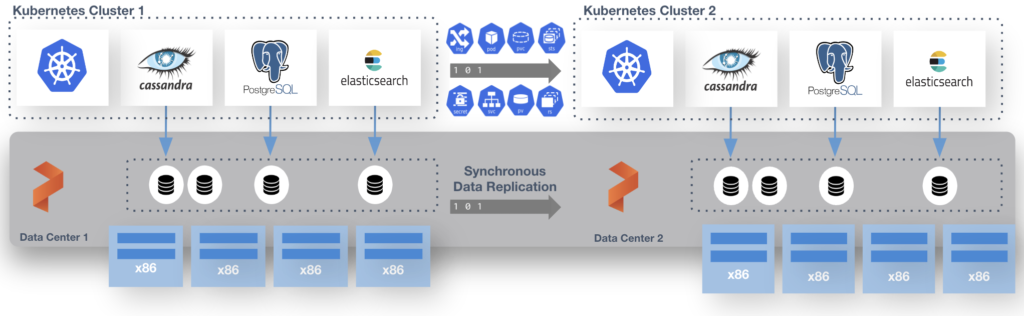
This is done with a shared etcd between the two distinct TKG clusters. That etcd can run at a third site where you would run the “witness node”. I run this in a standalone admin k8s cluster that runs all my internal services like etcd, externaldns, harbor and more. Just so you know this etcd is used by Portworx Enterprise only and is not the one used by k8s.
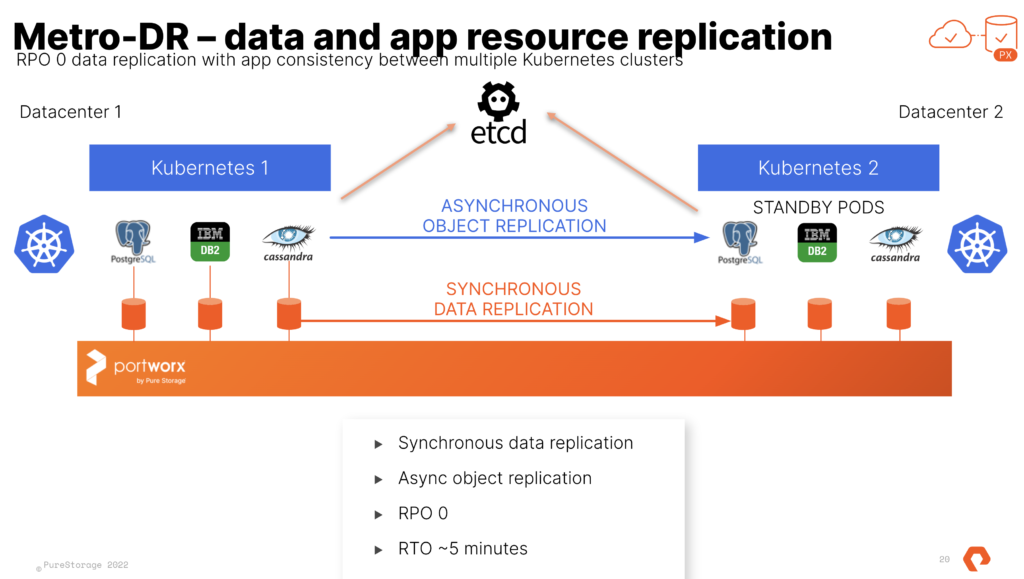
At the end of the process you have 2 TKG Clusters and 1 Portworx Cluster. We use Async schedules to copy the objects between clusters. The data is synchronously copied between nodes only limited by the latency. (Max for sync-dr is 10ms). This means the deployment for Postgres or Cassandra in the picture above is copied on a schedule and the non-live or target cluster is scaled to 0 replicas. The RPO is 0 since the data is copied instantly, the RTO is based on how fast you can spin up the replicas on the target.
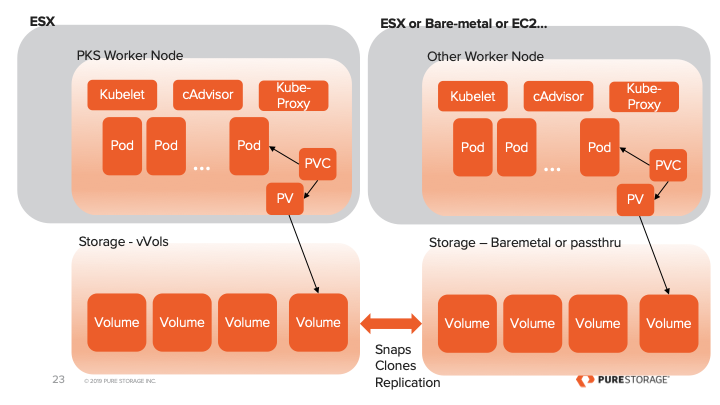
Even though Portworx Enterprise and Metro-DR works with any storage target supported by Tanzu (VSAN, NFS Datastores, VMFS Datastores, other vVOls). The SPBM and vVols integrations from Pure Storage with the FlashArray are the most used anywhere. The effort for the integration and collaboration betweet Pure and VMware Engineering is amazing. Cody Hosterman and his team have done some amazing things. Metro-DR works great with Pure vVols and is the perfect cloud-native compliment to your stretched vVols VM’s using FlashArray ActiveCluster. If you are interested in using both together let your Pure Storage team know or send me a message on the twitter and I will track them down for you.